What Is LLM Visibility? Definition, Measurement, and 2026 Benchmarks
Read the postDateApr 14, 2026
CategoryResearch

The first two posts in this series treated each day's AI response as a self-contained event. We asked which features predicted whether a brand would still be there tomorrow, and where on the ladder it would land, but we never asked whether the AI was returning to the same source material each day. This post does. We call a cited URL an anchor when an AI platform cited it the day before for the same brand on the same prompts and cites it again today. Anchors are the closest thing in our data to evidence that the AI is doing stable retrieval on a prompt rather than running fresh searches each time. Two questions follow. First, do platforms that re-cite the same URLs every day also tend to re-recommend the same brands? Second, if a brand had anchored citations going into today's response, does that predict where the brand will land tomorrow? The first answer turns out to be the more interesting one. In our data the platform with the highest URL anchor rate (Perplexity, at 62.4% of yesterday's URLs re-cited today) is also the platform with the lowest brand primary rate (6.7%). URL stability and brand stability look like different things in our 10-brand sample, and the model improvements we got from adding anchor features land in a different place than we expected. As with the previous two posts in this series, we read the patterns as suggestive rather than conclusive.
TL;DR
We call a cited URL an anchor when an AI platform cited it the day before for the same brand on the same prompts and cites it again today. Anchors are the closest thing in our data to evidence that an AI engine is doing stable retrieval on a prompt rather than running fresh searches each time. Perplexity returns to 62.4% of yesterday's cited URLs, twice the rate of any other AI platform we measured, yet has the lowest brand primary rate in our data (6.7%). Adding URL anchor features to yesterday's ordinal regression improved test accuracy from 47.5% to 54.5% and collapsed the Perplexity platform coefficient from +0.53 to +0.02. The actionable finding is that first-party anchored URLs predict roughly 3x faster promotion from secondary to primary (26.3% vs 8.9%); third-party anchors do almost nothing for brands trying to move up. The four new features were the URL anchor count, the URL anchor ratio, the domain-grain version of the anchor count, and a flag for whether any of the repeat-cited URLs sat on the brand's own domain. The model improvement is concentrated in places we did not expect. The Perplexity coefficient absorption is the biggest surprise; some of what yesterday's post called Perplexity personality may actually be Perplexity's URL anchoring rate. The strongest anchor coefficient in the augmented model is negative: the domain anchor count lands at −1.01 standardised, larger in absolute size than the brand-level competitor count. The directional read is that anchoring on many domains in the same response may be a marker of an enumerative response (many sources, many brands listed, any individual brand pushed down), so the practical lever appears to be which URLs anchor, not how many. As with the previous two posts in this series, a 10-brand sample can only tell us directional patterns.

Perplexity re-cites 62.4% of yesterday's URLs, twice the rate of any other platform we measured, yet has the lowest brand primary rate in the same data (6.7%).
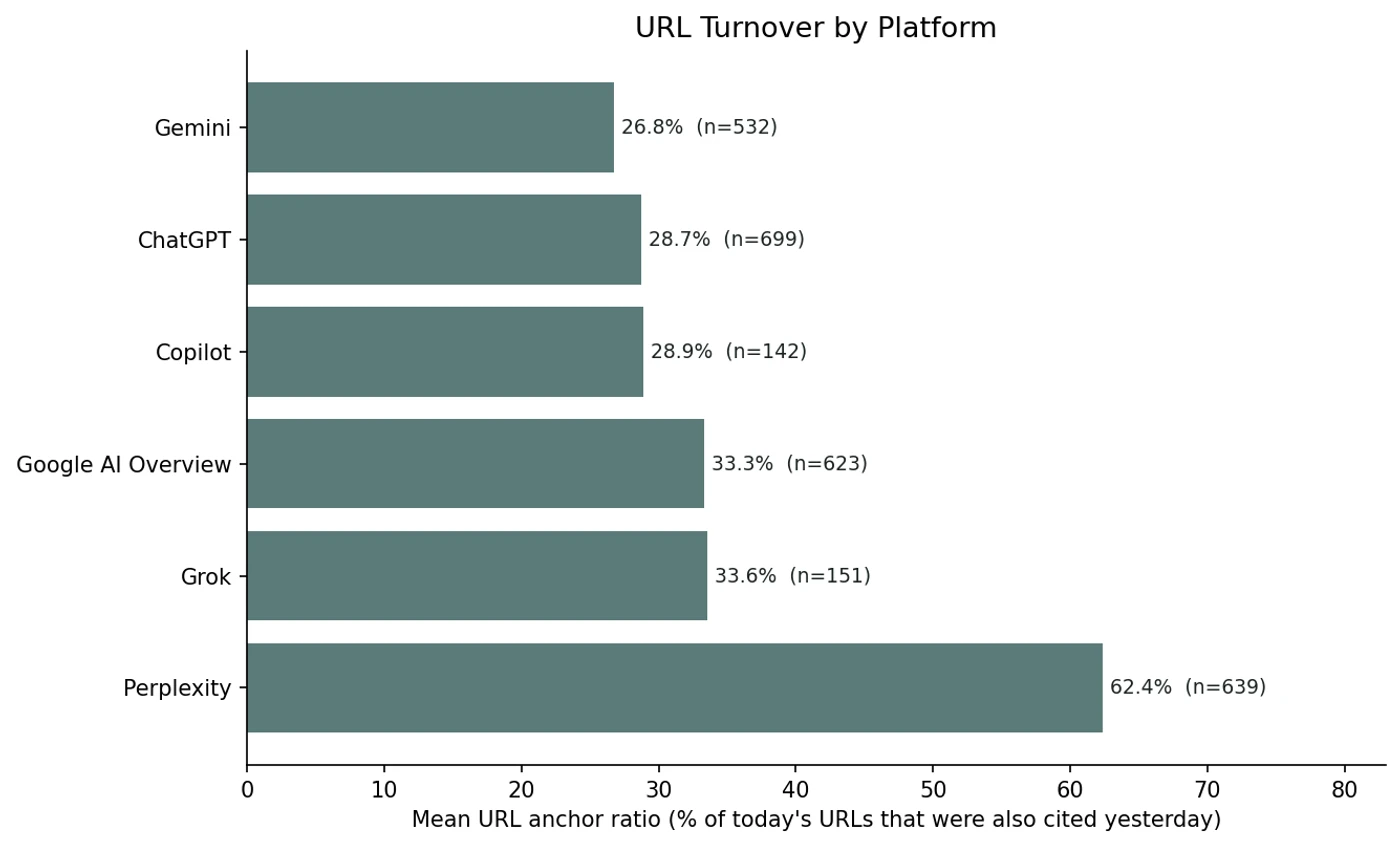
Perplexity returned to 62.4% of yesterday's cited URLs in our data, roughly twice the rate of any other platform we measured. Grok came in at 33.6%, Google AI Overview at 33.3%, Copilot at 28.9%, ChatGPT at 28.7%, Gemini at 26.8%. If URL persistence drove brand persistence, Perplexity would look like the platform where brands are stickiest.
In our data the opposite seems to hold. Perplexity had the lowest primary rate of any active platform in yesterday's position study (6.7%) and one of the lowest secondary rates as well. The pattern looks clean enough to push back on the obvious hypothesis: a platform that returns to the same source URLs every day may not be a platform that returns to the same brand recommendations.
Across 2,786 (brand, platform, day) cells with a prior measurement, Perplexity sits alone at the top with 62.4% URL re-cite rate; the other five platforms cluster between 26.8% and 33.6%.
We computed the URL anchor ratio for every (brand, platform, date) cell with a prior measurement: the share of today's cited URLs that were also cited the day before for the same brand on the same platform. Perplexity sits alone at the top, roughly twice the next platform. The other five platforms cluster between 26.8% and 33.6%, much closer to each other than any of them is to Perplexity.
| Platform | Cells | Mean URLs/cell | URL anchor ratio | Mean Jaccard |
|---|---|---|---|---|
| Perplexity | 639 | 94 | 62.4% | 47.0% |
| Grok | 151 | 552 | 33.6% | 21.0% |
| Google AI Overview | 623 | 97 | 33.3% | 20.1% |
| Copilot | 142 | 36 | 28.9% | 17.0% |
| ChatGPT | 699 | 243 | 28.7% | 16.5% |
| Gemini | 532 | 26 | 26.8% | 15.3% |
The volume per cell varies by an order of magnitude across platforms in our sample. Grok cells average 552 URLs each, Gemini just 26. The platforms doing the most URL retrieval do not appear to be the platforms re-citing the most. And the platform with the highest URL persistence in our data also looks like the platform with the lowest brand persistence.
The Perplexity platform coefficient drops from +0.53 to +0.02 when URL anchor features are added; some of what yesterday's post called platform personality was platform anchor rate.
We re-fit yesterday's ordinal regression with four new features. The URL anchor count is the number of URLs cited today that were also cited the day before for the same brand on the same platform. The URL anchor ratio is that count divided by the total URLs cited today. The domain anchor count applies the same idea at the registrable-domain grain (so a brand cited at blog.example.com yesterday and shop.example.com today still counts as anchored at the domain level). The first-party anchor flag records whether any of those repeat-cited URLs sit on the brand's own domain. Test-set accuracy improved from 47.5% to 54.5%, and the ordinal MAE dropped from 0.563 to 0.499. Both gains are modest but consistent on the same train/test split.
The improvement appears to land in places we did not expect. The Perplexity platform coefficient, which yesterday's study reported at +0.53 standardised, collapses to +0.02 in the augmented model. The Gemini coefficient drops from +1.32 to +0.78, a delta of −0.53. The Copilot coefficient extends further, from −2.46 to −2.89. Adding URL-level features does not just complement the platform features in our data; it appears to absorb a meaningful chunk of them. One reading is that some of what yesterday's post called platform personality may actually be platform anchor rate.
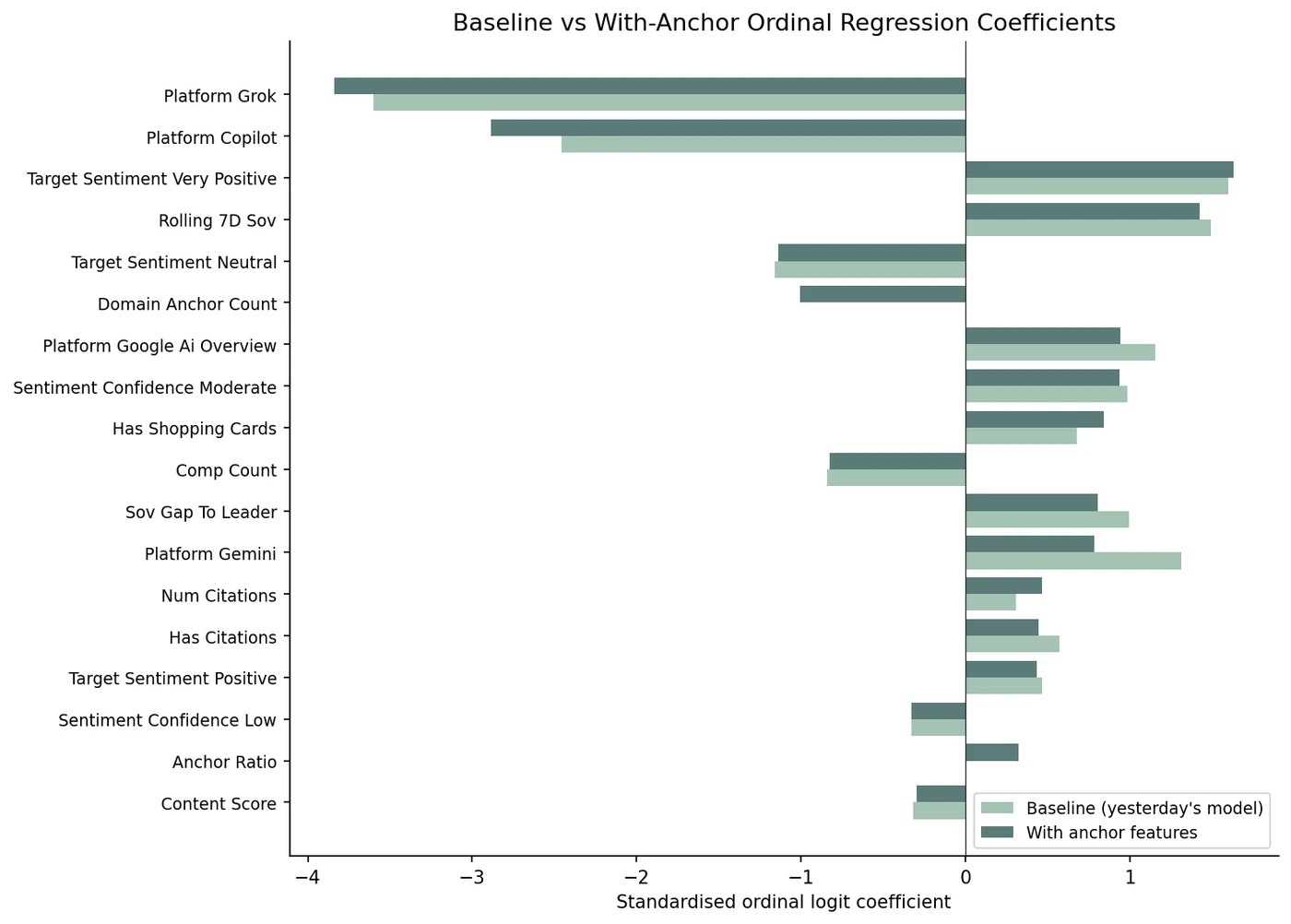
Four features moved test accuracy by seven points and seemed to shift the platform structure underneath. The model is not just better in our data; it appears to be making different decisions, and the largest single shift lands on the platform whose URL behaviour was the most distinctive in the previous section.
Among brands at secondary, those with a first-party anchored URL get promoted to primary at 26.3% (n=76) vs 8.9% for brands with only third-party anchored URLs (n=314), roughly 3x.
Splitting anchored citations by whether they sit on the brand's own domain produced what looks like the most actionable result. Among brands at secondary on day N, those with at least one anchored first-party URL got promoted to primary at 26.3% (n=76). Brands at secondary with only third-party anchored URLs got promoted at 8.9% (n=314), roughly a 3x difference. The same pattern appears for breaking through from absent: 4.1% with first-party anchors versus 0.7% without (n=218 vs 1797).
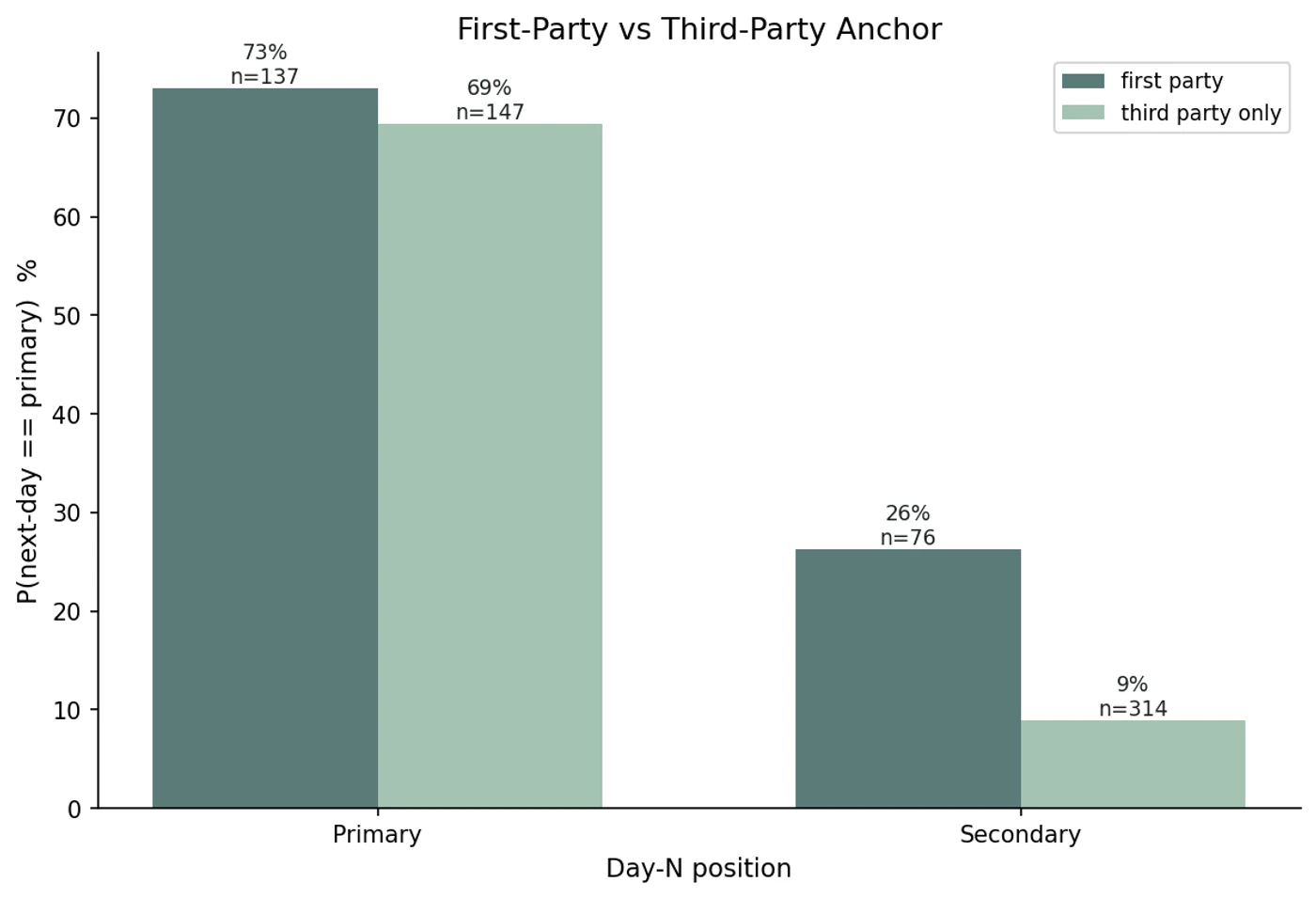
For brands already at primary, first-party anchors barely move the needle in our data (73.0% vs 69.4%). First-party anchored URLs do not appear to hold position; they appear to predict the upward move. If the asymmetry holds at larger scale, it may be the most directly useful finding for brands deciding which page to optimise next. Anchoring a third-party page on a comparison site does not look like it moves you up the way anchoring a page on your own domain does.
The domain anchor count lands at −1.01 standardised in the augmented model, larger in absolute size than the brand-level competitor count (−0.83). Anchoring on many domains may be a marker of enumerative responses.
The strongest anchor coefficient in the augmented model is negative. The domain-grain anchor count lands at −1.01 standardised, larger in absolute size than the brand-level competitor count (−0.83) and comparable to the shopping cards coefficient (+0.84). One plausible reading is that when the AI is anchoring on many distinct domains in the same response, the response is structurally enumerative; many sources, many brands listed, any individual brand pushed down.
Anchoring may not mean “the AI commits to your sources.” In our data it looks closer to “the AI is in a stable retrieval mode for this prompt,” and stable retrieval modes appear to pack more brands into the answer. The first-party flag is positive (+0.09), the URL anchor ratio is positive (+0.32), and the URL anchor count is positive (+0.20), so the directional read across the four features looks consistent: which URLs anchor may matter more than how many.
Total citation volume tells you the AI is doing stable retrieval on a prompt; it does not tell you which brand benefits. The brand-level lever is which URLs anchor, not how many.
The practical implication looks narrower than the hypothesis we started with. Total citation volume and total anchor count seem to tell you the AI is doing stable retrieval on a prompt; they do not appear to tell you which brand benefits from that retrieval. The brand-level levers we found in our data are about which URLs anchor, not how many. A brand trying to move from secondary to primary in our sample benefits roughly 3x from having a first-party page in the AI's anchored set; the same brand sees almost no benefit from third-party anchored mentions.
For brands already at primary, anchors do not appear to hold the position; sentiment, momentum, and platform identity look like they carry that work in the model. The overall accuracy gain from adding URL-level features (47.5% to 54.5%) is real but incremental, and AI selection within a prompt still appears to be doing more than retrieval inertia explains. As with the previous two posts in this series, a 10-brand sample can only tell us directional patterns rather than firm conclusions, and the first thing we expect to improve at scale is the ability to separate the effect of any single anchored URL from the effect of having many.
Sill monitors ChatGPT, Gemini, Perplexity, Google AI Overviews, Copilot, and Grok daily, captures every cited URL, and flags which ones show up day after day on the prompts that matter to your brand.
mord.LogisticAT. github.com/fabianp/mordTell us about your brand and we'll be in touch to walk you through Sill.